背景
データ分析基盤の信頼性向上には、データパイプラインの自動化が必要不可欠です。手動運用ではヒューマンエラーや運用コストの増大が懸念されるため、CI/CDの仕組みを導入して自動化することが求められています。GitHub Actionsは、GitHubとの親和性が高く、コミュニティが提供するActions(再利用可能な自動化タスクのテンプレート)が豊富なため、データパイプラインの自動化を手軽に素早く実現できるツールです。しかし、実際の運用環境では、パフォーマンスの最適化やコスト管理など、いくつか注意すべきポイントがあります。
本記事では、基本的なデータパイプラインの実装例とともに、ランナー選択、並列処理の活用、キャッシュの利用といったパフォーマンス改善方法について解説します。
データパイプライン向けワークフロー実装例
まずは基本的なデータパイプラインについてご紹介します。以下の構成例では、毎日3:00に定期的に「output.csv」というデータをAmazon Simple Storage Service(Amazon S3)にアップロードする場合を想定しています。データパイプラインは大きく分けて「Extract(抽出)」「Transform(加工)」「Load(ロード)」の3つのプロセスを経てアウトプットを生成するのが一般的です。
構成例

| リポジトリ | GitHub |
| CI/CD | GitHub Actions |
| state管理場所 | Amazon Simple Storage Service(Amazon S3) |
| 加工済みデータの格納場所 | Amazon Simple Storage Service(Amazon S3) |
パイプラインのコード例
この構成例をコード化すると以下のようになります。
name: ETL Pipeline
on:
schedule:
- cron: "0 3 * * *" # 毎日AM3:00に実行
jobs:
# データ取得と環境準備
extract:
runs-on: ubuntu-latest
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.10'
- name: Install dependencies
run: |
python -m pip install --upgrade pip
pip install -r requirements.txt
- name: Get raw data from S3
run: aws s3 cp s3://bucket/raw_data.csv ./input.csv
id: extract
# データ加工処理
transform:
needs: extract
runs-on: ubuntu-latest
steps:
- name: Transform csv
run: |
python transform.py \
--input ./input.csv \
--output ./output.csv
env:
PROCESSING_THREADS: 4
# 加工済みデータをアップロード
load:
needs: transform
runs-on: ubuntu-latest
steps:
- name: Upload to S3
uses: aws-actions/configure-aws-credentials@v4
with: role-to-assume: arn:aws:iam::123456789012:role/my-github-role
role-session-name: GithubActionsSession
aws-region: ap-northeast-1
run: aws s3 cp output.csv s3://your-data-bucket/小規模なものであれば、こちらのETLパイプラインでやりたいことを最低限実現することは可能です。一方で、中〜大規模なCI/CDを組む際は、これでは不十分な場合があり、幾つか改善の余地があるコードとなっています。パフォーマンス改善のポイントを確認していきましょう。
パフォーマンス改善のポイント
1. 適切なランナー選択
jobs:
extract:
# 特別な理由が無ければ ubuntu-latest を使用する
runs-on: ubuntu-latestWindowsやmacOSのランナーは、Ubuntuのランナーに比べ同一処理の料金が2倍以上かかる仕様となっています。特別な理由が無ければ ubuntu-latest を使用するのが無難です。
また、Amazon Elastic Compute Cloud(EC2)やオンプレミスサーバーをセルフホステッドランナーとして利用することで、パフォーマンスとコスト面でメリットが得られる場合があります。
例:
- Amazon Elastic Compute Cloud(c5.2xlarge)をセルフホステッドランナー運用
- Spot Instancesとすることでコスト削減を実現
セルフホステッドランナーは、GitHub画面の「Settings > Actions > Runners」から「New self-hosted runner」を押下することで作成することができます。

お持ちのサーバーでいくつかのコマンドを叩くだけで、簡単に構築することができます。(具体的な構築方法については、詳しく手順化して下さってる方がいますので割愛します。参考:GitHub Actionsのセルフホステッドランナーを構築する)
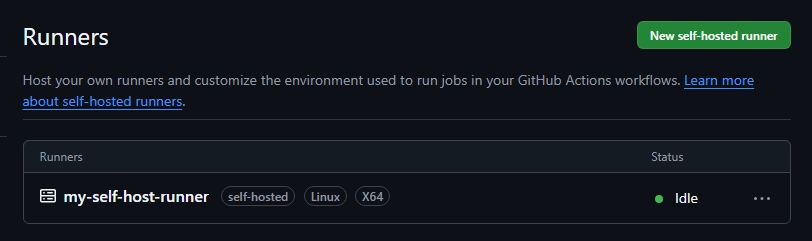
ランナーが正常に動作しネットワークの疎通も取れていると「Status」はIdleと表示されます。この状態で、パイプラインのymlファイルで「runs-on: self-hosted」を指定することで、セルフホステッドランナーを使用したCI/CDを実現することができます。
ただし、自前でサーバーを管理するコストがかかるため、運用方針や要件に合わせて何を優先するかを天秤にかける必要はあります。
2. 並列処理の活用
大量データの処理では、データを複数のシャードに分割して並列実行することで、全体の処理時間を大幅に短縮できる場合があります。以下の例では、1つの処理を4つのシャードに分けて並列実行する例です。
jobs:
shard-1:
runs-on: ubuntu-latest
steps:
- name: データ処理(Shard 1)
run: python process.py --shard 1
shard-2:
runs-on: ubuntu-latest
steps:
- name: データ処理(Shard 2)
run: python process.py --shard 2
shard-3:
runs-on: ubuntu-latest
steps:
- name: データ処理(Shard 3)
run: python process.py --shard 3
shard-4:
runs-on: ubuntu-latest
steps:
- name: データ処理(Shard 4)
run: python process.py --shard 4この例では、理論上、処理時間を1/4に短縮することができ、大幅な時間短縮とランニングコストの削減が期待できます。
3. キャッシュの活用
依存パッケージの再インストールや、Dockerレイヤーのビルド時間を短縮するには、キャッシュ機能が有効です。これにより再構築にかかる時間を短縮することができます。
以下は、pythonの依存パッケージをキャッシュする例です。
- name: Cache pip dependencies
uses: actions/cache@v4
with:
path: ~/.cache/pip
key: ${{ runner.os }}-pip-${{ hashFiles('**/requirements.txt') }}
restore-keys: |
${{ runner.os }}-pip-特にデータパイプラインでは、パイプライン内で同じ作業が繰り返されるケースが多く、大量データを処理した結果をキャッシュとして保持することで、同じ処理を何度も行わなくて済みます。
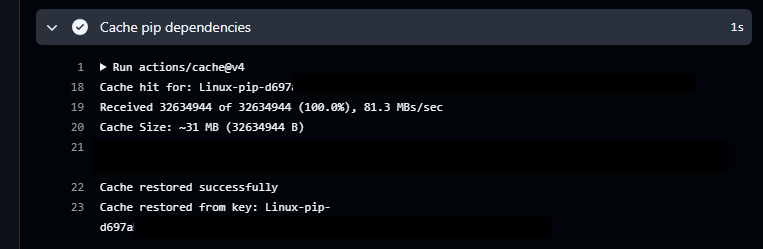
GitHub Actionsのログ画面で、以下のように「Cache hit…」のようなログが表示されていれば、キャッシュヒットしていることが確認できます。
最後に
今回は、GitHub Actionsを用いたデータパイプラインのCI/CD実装において、具体的なデータパイプラインの実装例とともに、パフォーマンス改善のポイントについて解説しました。
実際の運用では、小規模なパイプラインで設定を検証し、徐々にスケールアップして本番環境に展開するアプローチでリスクを抑えつつCI/CDの仕組みを導入することができます。是非、実践してみてください。